数组
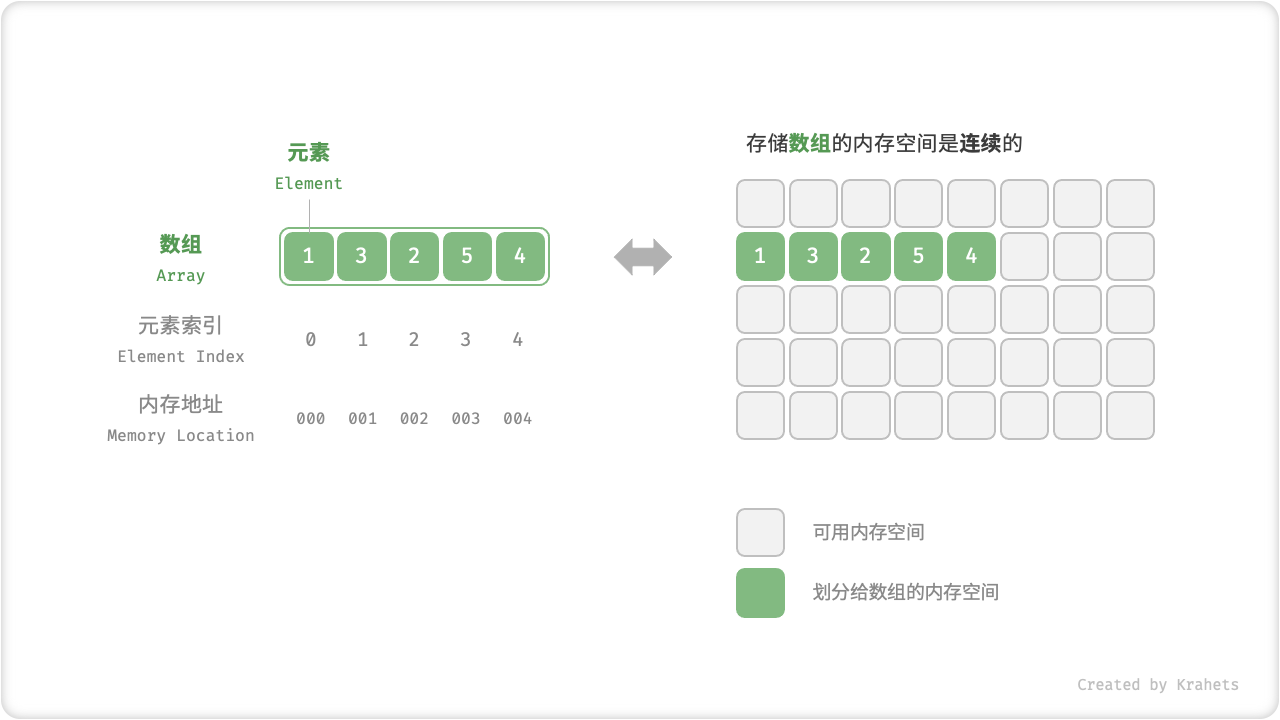
「数组 Array」是一种将 相同类型元素 存储在 连续内存空间 的数据结构,将元素在数组中的位置称为元素的「索引 Index」。
-
数组名 :数组的名字
-
数组元素:就是存放在数组里面的数据
-
数组索引:就是数组里面连续存储空间的编号,从0开始。而从0开始的原因是根据地址计算公式,索引本质上表示的是内存地址偏移量,首个元素的地址偏移量是 0 ,所以索引值也是 0 。
-
length :数组的属性长度,数组名.length拿到数组的长度
-
数组的声明:数据类型[] 数组名
int[] ages; // 声明一个int类型的数组ages,数组内元素均为int类型 String[] names;// 声明一个String类型的数组names,数组内元素均为String类型 // 也可以用 int ages[]声明,但是不推荐 -
数组的赋值与取值:
数组在定义后,必须**初始化「赋值」**才能使用。所谓初始化,就是在堆内存中给数组分配存储空间,并为每一 个元素赋上初始值,有两种方式:
-
动态创建:
**语法 **:数据类型[] 数组名 = new 数据类型[长度] ,长度不能为负数,默认是int类型,最大就是int最大值。
int[] arr1 = new int[3]; // 动态创建了一个int类型的数组arr1,长度3 -
静态创建:
语法:第一个方式是常用方式,第二个方式作为了解。
数据类型[] 数组名 = {值1, 值2, 值3…..};
数据类型[] 数组名 = new 数据类型[]{值1,值2,值3…..};
int[] arr2 = {1,3,5,8,9}; // 静态创建了一个长度为5,int类型的数组arr2,赋值元素 :1,3,5,8,9 -
数组赋值
在赋值后,如果数组原位置有值则会覆盖。
语法:数组名[下标] = 值;
arr1[0] = 1; // 给数组arr1第1个元素赋值1 arr1[1] = 2; // 给数组arr1第2个元素赋值2 arr1[2] = 3; // 给数组arr1第3个元素赋值3 -
数组取值
System.out.println("第1个元素 : " + arr[0]); // 直接打印第1个元素 int box = arr1[2]; // 将数组的第三个元素取出,赋值给box -
数组常用操作
数组遍历:就是将数组中每一个元素取出来。
/* 遍历数组 */ void traverse(int[] nums) { int count = 0; // 方法1:通过索引遍历数组 for (int i = 0; i < nums.length; i++) { count++; } // 方法2:foreach直接遍历数组 for (int num : nums) { count++; } }数组查找:通过遍历数组,查找数组内的指定元素,并输出对应索引。
/* 在数组中查找指定元素 */ int find(int[] nums, int target) { for (int i = 0; i < nums.length; i++) { if (nums[i] == target) return i; } return -1; } -
数组中常见异常:
ArrayIndexOutOfBoundsException:数组越界异常
指数组下标变量的取值超过了初始定义时的大小,导致对数组元素的访问出现在数组的范围之外
NullPointerException:空指针异常
一个已宣告但并未指向一个有效对象的指针,例如一个对象为
null,调用其方法或访问其字段就会产生NullPointerException
-
-
数组的优点:
在数组中访问元素非常高效。这是因为在数组中,计算元素的内存地址非常容易。给定数组首个元素的地址、和一个元素的索引,利用以下公式可以直接计算得到该元素的内存地址,从而直接访问此元素。
其中,数组存储在栈内,存储内容为首元素地址,具体数组的元素存储在堆内。
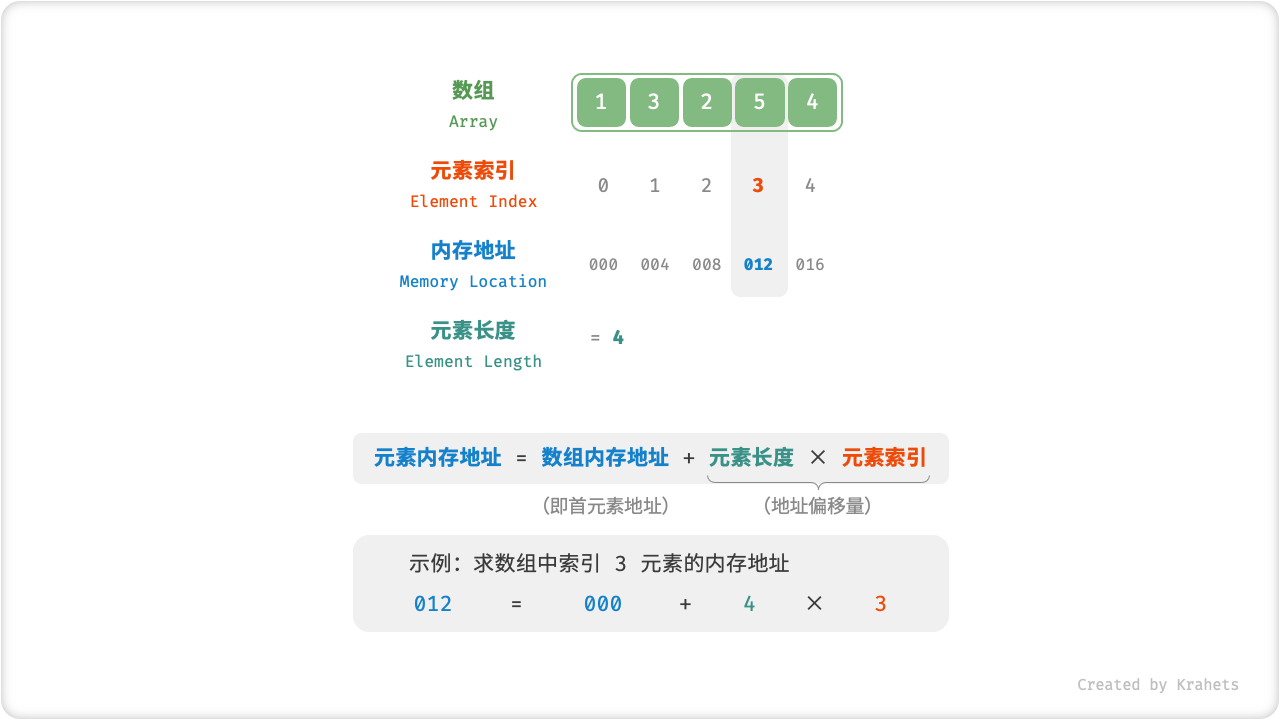
注:其中的 元素长度 与 数组长度 概念不同。元素长度与数组类型有关,例如byte与int类型的数组的元素长度是不同的;数组长度就是数组里数的个数。
访问元素的高效性带来了许多便利。例如,我们可以在 O(1) 时间内随机获取一个数组中的元素。
/* 随机返回一个数组元素 */ int randomAccess(int[] nums) { int randomIndex = ThreadLocalRandom.current(). nextInt(0, nums.length); int randomNum = nums[randomIndex]; return randomNum; } -
数组的缺点:
数组在初始化后长度不可变。由于系统无法保证数组之后的内存空间是可用的,因此数组长度无法扩展。而若希望扩容数组,则需新建一个数组,然后把原数组元素依次拷贝到新数组,在数组很大的情况下,这是非常耗时的。
/* 扩展数组长度 */ int[] extend(int[] nums, int enlarge) { // 初始化一个扩展长度后的数组 int[] res = new int[nums.length + enlarge]; // 将原数组中的所有元素复制到新数组 for (int i = 0; i < nums.length; i++) { res[i] = nums[i]; } // 返回扩展后的新数组 return res; }数组中插入或删除元素效率低下。假设我们想要在数组中间某位置插入一个元素,由于数组元素在内存中是“紧挨着的”,它们之间没有空间再放任何数据。因此,我们不得不将此索引之后的所有元素都向后移动一位,然后再把元素赋值给该索引。删除元素也是类似,需要把此索引之后的元素都向前移动一位。总体看有以下缺点:
-
时间复杂度高:数组的插入和删除的平均时间复杂度均为 O(N) ,其中 N 为数组长度。
-
丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会被丢失。
-
内存浪费:我们一般会初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是我们不关心的,但这样做同时也会造成内存空间的浪费。
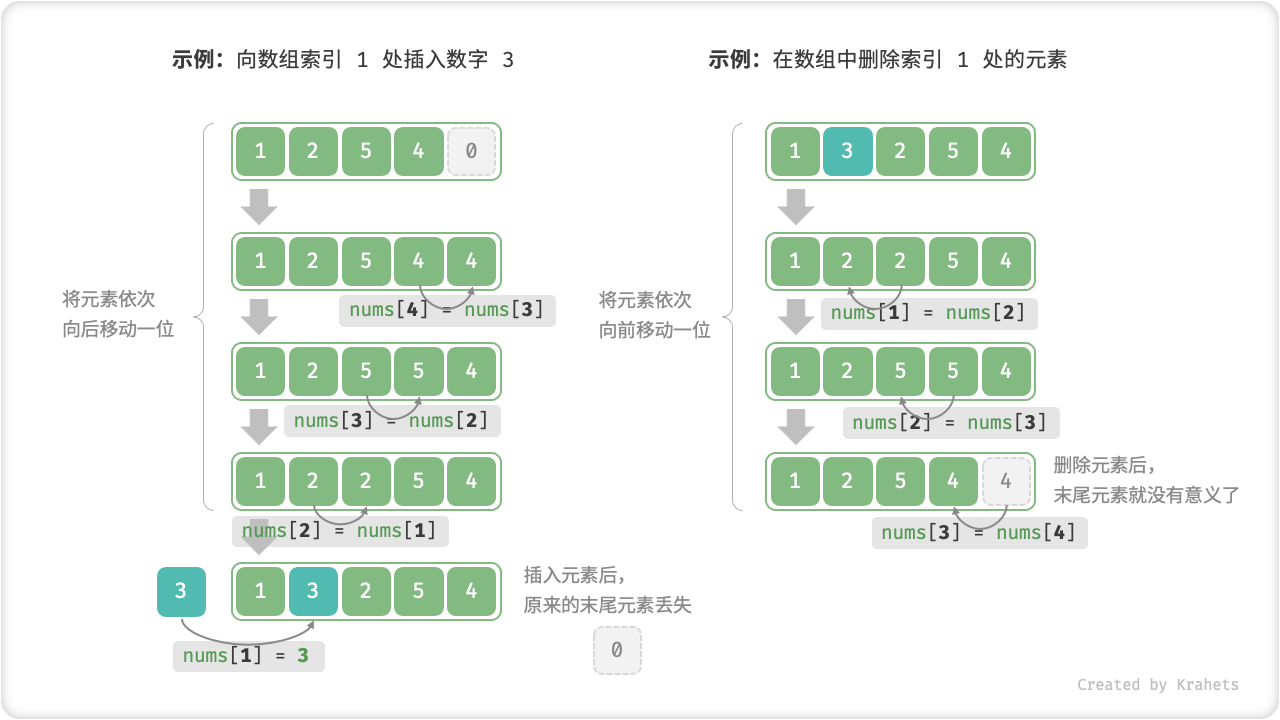
/* 在数组的索引 index 处插入元素 num */ void insert(int[] nums, int num, int index) { // 把索引 index 以及之后的所有元素向后移动一位 for (int i = nums.length - 1; i > index; i--) { nums[i] = nums[i - 1]; } // 将 num 赋给 index 处元素 nums[index] = num; } /* 删除索引 index 处元素 */ void remove(int[] nums, int index) { // 把索引 index 之后的所有元素向前移动一位 for (int i = index; i < nums.length - 1; i++) { nums[i] = nums[i + 1]; } } -
-
数组的典型应用
随机访问。如果我们想要随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现样本的随机抽取。
二分查找。例如查字典,我们可以将字典中的所有字按照拼音顺序存储在数组中,然后使用与日常查纸质字典相同的“翻开中间,排除一半”的方式,来实现一个查电子字典的算法。
深度学习。神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。