算法
-
算法定义:
「算法 Algorithm」是在有限时间内解决问题的一组指令或操作步骤。算法具有以下特性:
- 问题是明确的,需要拥有明确的输入和输出定义。
- 解具有确定性,即给定相同输入时,输出一定相同。
- 具有可行性,可在有限步骤、有限时间、有限内存空间下完成。
- 独立于编程语言,即可用多种语言实现。
-
数据结构定义:
「数据结构 Data Structure」是在计算机中组织与存储数据的方式。为了提高数据存储和操作性能,数据结构的设计原则有:
- 空间占用尽可能小,节省计算机内存。
- 数据操作尽量快,包括数据访问、添加、删除、更新等。
- 提供简洁的数据表示和逻辑信息,以便算法高效运行。
数据结构的设计是一个充满权衡的过程,这意味着如果获得某方面的优势,则往往需要在另一方面做出妥协。例如,链表相对于数组,数据添加删除操作更加方便,但牺牲了数据的访问速度;图相对于链表,提供了更多的逻辑信息,但需要占用更多的内存空间。
-
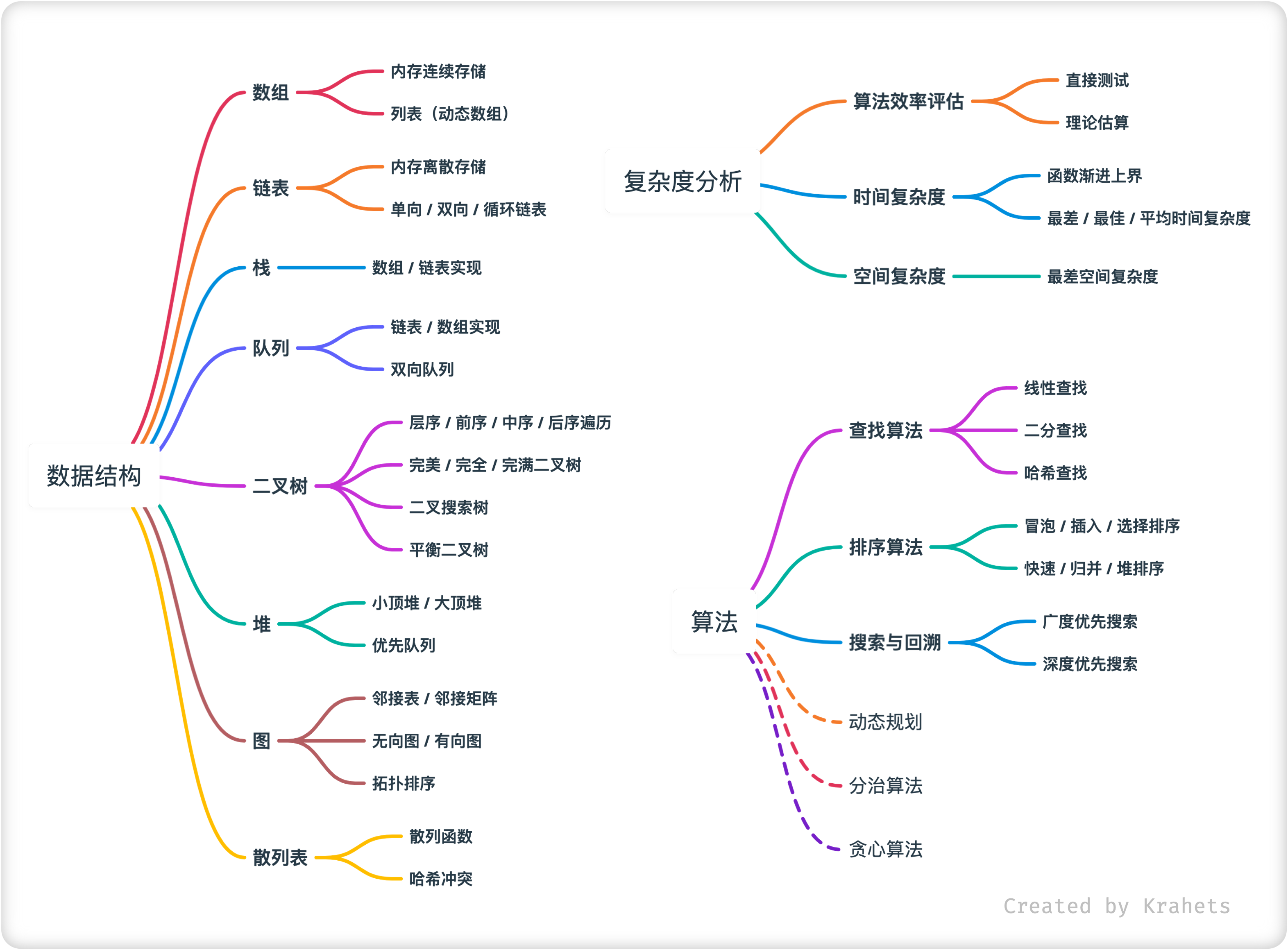
数据结构与算法的关系:
「数据结构」与「算法」是高度相关、紧密嵌合的,体现在:
-
数据结构是算法的底座。数据结构为算法提供结构化存储的数据,以及操作数据的对应方法。
-
算法是发挥数据结构优势的舞台。数据结构仅存储数据信息,结合算法才可解决特定问题。
-
算法有对应最优的数据结构。给定算法,一般可基于不同的数据结构实现,而最终执行效率往往相差很大。
-
复杂度分析
算法效率评估
算法的设计目标是什么,或者说,如何来评判算法的好与坏。整体上看,我们设计算法时追求两个层面的目标:找到问题解法 与 寻求最优解法。
算法效率则是主要评价维度,包括:
-
时间效率,即算法的运行速度的快慢。
-
空间效率,即算法占用的内存空间大小。
注:大多数情况下,时间都是比空间更宝贵的,只要空间复杂度不要太离谱、能接受就行,因此以空间换时间最为常用。
-
效率评估方法–实际测试
假设我们现在有算法 A 和 算法 B ,都能够解决同一问题,现在需要对比两个算法之间的效率。最直接的方式,就是找一台计算机,把两个算法都完整跑一遍,并监控记录运行时间和内存占用情况。这种评估方式能够反映真实情况,但是也存在弊端:
-
难以排除测试环境的干扰因素。硬件配置会影响到算法的性能表现。例如,在某台计算机中,算法 A 比算法 B 运行时间更短;但换到另一台配置不同的计算机中,可能会得到相反的测试结果。这意味着我们需要在各种机器上展开测试,而这是不现实的。
-
展开完整测试非常耗费资源。随着输入数据量的大小变化,算法会呈现出不同的效率表现。比如,有可能输入数据量较小时,算法 A 运行时间短于算法 B ,而在输入数据量较大时,测试结果截然相反。因此,若想要达到具有说服力的对比结果,那么需要输入各种体量数据,这样的测试需要占用大量计算资源。
-
-
效率评估方法–理论估算
估算方法称为「复杂度分析 Complexity Analysis」或「渐近复杂度分析 Asymptotic Complexity Analysis」。
- 复杂度分析评估随着输入数据量的增长,算法的运行时间和占用空间的增长趋势。根据时间和空间两方面,复杂度可分为「时间复杂度 Time Complexity」和「空间复杂度 Space Complexity」。
- 复杂度分析克服了实际测试方法的弊端。一是独立于测试环境,分析结果适用于所有运行平台。二是可以体现不同数据量下的算法效率,尤其是可以反映大数据量下的算法性能。
时间复杂度
-
统计算法运行时间
运行时间能够直观且准确地体现出算法的效率水平,想要准确预估一段代码的运行时间,需要做:
-
首先需要 确定运行平台 ,包括硬件配置、编程语言、系统环境等,这些都会影响到代码的运行效率。
-
评估 各种计算操作的所需运行时间 ,例如加法操作
+需要 1 ns ,乘法操作*需要 10 ns ,打印操作需要 5 ns 等。 -
根据代码统计所有计算操作的数量,并将所有操作的执行时间求和,即可得到运行时间。
例如:以下代码,输入数据大小为 n ,根据以上方法,可以得到算法运行时间为 6n+12 ns 。
// 在某运行平台下 void algorithm(int n) { int a = 2; // 1 ns a = a + 1; // 1 ns a = a * 2; // 10 ns // 循环 n 次 for (int i = 0; i < n; i++) { // 1 ns ,每轮都要执行 i++ System.out.println(0); // 5 ns } }但实际上, 统计算法的运行时间既不合理也不现实。首先,我们不希望预估时间和运行平台绑定,毕竟算法需要跑在各式各样的平台之上。其次,我们很难获知每一种操作的运行时间,这为预估过程带来了极大的难度。
-
-
统计时间增长趋势
「时间复杂度分析」采取了不同的做法,其统计的不是算法运行时间,而是 算法运行时间随着数据量变大时的增长趋势 。
“时间增长趋势”这个概念比较抽象,借助一个例子来理解。设输入数据大小为 n ,给定三个算法
A,B,C。-
算法
A只有 1 个打印操作,算法运行时间不随着 n 增大而增长。我们称此算法的时间复杂度为「常数阶」。 -
算法
B中的打印操作需要循环 n 次,算法运行时间随着 n 增大成线性增长。此算法的时间复杂度被称为「线性阶」。 -
算法
C中的打印操作需要循环 1000000 次,但运行时间仍与输入数据大小 n 无关。因此C的时间复杂度和A相同,仍为「常数阶」。
// 算法 A 时间复杂度:常数阶 void algorithm_A(int n) { System.out.println(0); } // 算法 B 时间复杂度:线性阶 void algorithm_B(int n) { for (int i = 0; i < n; i++) { System.out.println(0); } } // 算法 C 时间复杂度:常数阶 void algorithm_C(int n) { for (int i = 0; i < 1000000; i++) { System.out.println(0); } }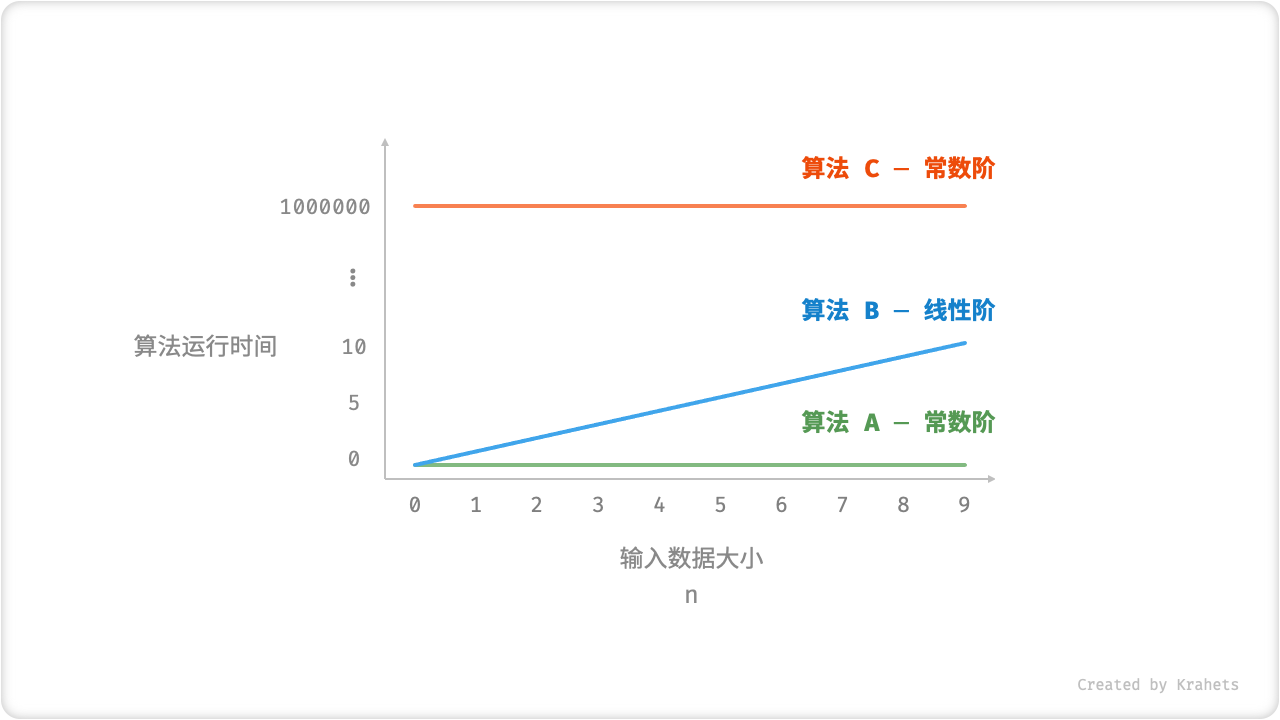
相比直接统计算法运行时间,时间复杂度分析的好处有:
-
时间复杂度可以有效评估算法效率。算法
B运行时间的增长是线性的,在 n>1 时慢于算法A,在 n>1000000 时慢于算法C。实质上,只要输入数据大小 n 足够大,复杂度为「常数阶」的算法一定优于「线性阶」的算法,这也正是时间增长趋势的含义。 -
时间复杂度的推算方法更加简便。在时间复杂度分析中,我们可以将统计「计算操作的运行时间」简化为统计「计算操作的数量」,这是因为,无论是运行平台还是计算操作类型,都与算法运行时间的增长趋势无关。因而,我们可以简单地将所有计算操作的执行时间统一看作是相同的“单位时间”,这样的简化做法大大降低了估算难度。
-
时间复杂度也存在一定的局限性。比如,虽然算法
A和C的时间复杂度相同,但是实际的运行时间有非常大的差别。再比如,虽然算法B比C的时间复杂度要更高,但在输入数据大小 n 比较小时,算法B是要明显优于算法C的。对于以上情况,我们很难仅凭时间复杂度来判定算法效率高低。然而,即使存在这些问题,计算复杂度仍然是评判算法效率的最有效且常用的方法。
-
-
函数渐近上界
设算法「计算操作数量」为 T(n) ,其是一个关于输入数据大小 n 的函数。例如,以下算法的操作数量为 T(n) = 3 + 2n
void algorithm(int n) { int a = 1; // +1 a = a + 1; // +1 a = a * 2; // +1 // 循环 n 次 for (int i = 0; i < n; i++) { // +1(每轮都执行 i ++) System.out.println(0); // +1 } }T(n) 是个一次函数,说明时间增长趋势是线性的,因此易得时间复杂度是线性阶。
将线性阶的时间复杂度记为 O(n) ,这个数学符号被称为「大 O 记号 Big-O Notation」,代表函数 T(n) 的「渐近上界 asymptotic upper bound」。
我们要推算时间复杂度,本质上是在计算「操作数量函数 T(n) 」的渐近上界。它的数学定义是。
若存在正实数c和实数n0,使得对于所有的 n > n0 ,均有 T(n) <= c*f(n) 则可认为f(n)给出了T(n)的一个渐近上界,记为 T(n) = O(f(n))具体推算方法与常见类型:
https://www.hello-algo.com/chapter_computational_complexity/time_complexity/
空间复杂度
「空间复杂度 Space Complexity」统计算法使用内存空间随着数据量变大时的增长趋势。这个概念与时间复杂度很类似。
与时间复杂度不同的是,一般只关注「最差空间复杂度」。这是因为内存空间是一个硬性要求,我们必须保证在所有输入数据下都有足够的内存空间预留。
最差空间复杂度中的“最差”有两层含义,分别为输入数据的最差分布、算法运行中的最差时间点。
-
算法相关空间
算法运行中,使用的内存空间主要有以下几种:
-
「输入空间」用于存储算法的输入数据;
-
「暂存空间」用于存储算法运行中的变量、对象、函数上下文等数据;
-
「输出空间」用于存储算法的输出数据;
Tips:通常情况下,空间复杂度统计范围是「暂存空间」+「输出空间」。
通常「暂存空间」分为三部分:
-
「暂存数据」用于保存算法运行中的各种 常量、变量、对象 等。
-
「栈帧空间」用于保存调用函数的上下文数据。系统每次调用函数都会在栈的顶部创建一个栈帧,函数返回时,栈帧空间会被释放。
-
「指令空间」用于保存编译后的程序指令,在实际统计中一般忽略不计。
/* 类 */ class Node { int val; Node next; Node(int x) { val = x; } } /* 函数 */ int function() { // do something... return 0; } int algorithm(int n) { // 输入数据 final int a = 0; // 暂存数据(常量) int b = 0; // 暂存数据(变量) Node node = new Node(0); // 暂存数据(对象) int c = function(); // 栈帧空间(调用函数) return a + b + c; // 输出数据 } -