XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言: 通过标签来描述数据的一门语言(标签有时也称为元素),标签的名字是可以自定义的,XML文件是由很多标签组成的。而标签名是可以自定义的。
XML 不会做任何事情。XML 被设计用来结构化、存储以及传输信息,例如 Jani 写给 Tove 的便签,存储为 XML。
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
XML 语言没有预定义的标签,而HTML 中使用的标签都是预定义的。HTML 文档只能使用在 HTML 标准中定义过的标签(如 <p>、<h1> 等等)。XML 允许创作者定义自己的标签和自己的文档结构。
XML 的作用:
-
把数据从 HTML 分离
通过 XML,数据能够存储在独立的 XML 文件中。这样就可以专注于使用 HTML/CSS 进行显示和布局,并确保修改底层数据不再需要对 HTML 进行任何的改变。通过使用几行 JavaScript 代码,就可以读取一个外部 XML 文件,并更新网页的数据内容。
-
简化数据共享
XML 数据以纯文本格式进行存储,因此提供了一种独立于软件和硬件的数据存储方法。这让创建不同应用程序可以共享的数据变得更加容易。
-
简化数据传输
由于可以通过各种不兼容的应用程序来读取数据,以 XML 交换数据降低了这种复杂性。
-
使数据更有用
不同的应用程序都能够访问数据,不仅仅在 HTML 页中,也可以从 XML 数据源中进行访问。通过 XML,数据可供各种阅读设备使用(掌上计算机、语音设备、新闻阅读器等),还可以供盲人或其他残障人士使用。
-
用于创建新的互联网语言
很多新的互联网语言是通过 XML 创建的。例如:
- XHTML
- 用于描述可用的 Web 服务 的 WSDL
- 作为手持设备的标记语言的 WAP 和 WML
- 用于新闻 feed 的 RSS 语言
- 描述资本和本体的 RDF 和 OWL
- 用于描述针对 Web 的多媒体 的 SMIL
XML的树结构
XML 文档必须包含根元素。该元素是所有其他元素的父元素。XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端,所有的元素都可以有子元素,父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。所有的元素都可以有文本内容和属性(类似 HTML 中)。
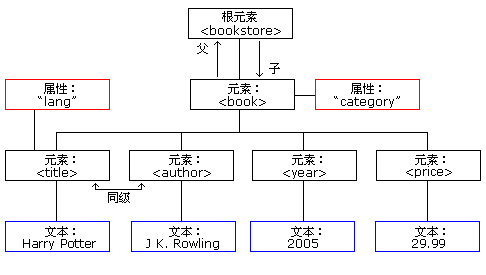
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
实例中的根元素是
<bookstore>。文档中的所有<book>元素都被包含在<bookstore>中。<book>元素有 4 个子元素:<title>、<author>、<year>、<price>。
XML语法
-
XML 声明
XML 声明文件的可选部分,如果存在需要放在文档的第一行第一列。
<?xml version="1.0" encoding="utf-8"?>version该属性是必须存在的encoding该属性不是必须的。打开当前xml文件的时候应该是使用什么字符编码表(一般取值都是UTF-8) 文档声明的字符编码必需和文档本身的编码一致standalone该属性不是必须的,描述XML文件是否依赖其他的xml文件,取值为yes/no以上实例包含 XML 版本( UTF-8 也是 HTML5, CSS, JavaScript, PHP, 和 SQL 的默认编码。
-
根元素
XML 必须包含根元素,它是所有其他元素的父元素。
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note> -
关闭标签
在 HTML 中,某些元素不必有一个关闭标签:
<p>This is a paragraph. <br>在 XML 中,省略关闭标签是非法的。所有元素都必须有关闭标签:
<p>This is a paragraph.</p> <br /> -
属性值
与 HTML 类似,XML 元素也可拥有属性(名称/值的对)。在 XML 中,XML 的属性值必须加引号。
<note date="12/11/2007"> <to>Tove</to> <from>Jani</from> </note> -
实体引用
在 XML 中,一些字符拥有特殊的意义。例如把字符 “<” 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。在 XML 中,有 5 个预定义的实体引用:
引用 被替代符号 << >> && '' "" 注:在 XML 中,只有字符 “<” 和 “&” 确实是非法的。大于号是合法的,但是也有实体引用,建议全部都用实体引用表示。
-
注释
在 XML 中编写注释的语法与 HTML 的语法很相似。
<!-- This is a comment --> -
标签命名规则
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
-
标签的属性
标准语法:
<person id="1"></person>id是属性名,1表示属性值,不管是数值还是其他都要使用引号引起来属性位置:写在单标记中或者写在双标记的开始标记中
-
注意事项
-
XML 标签大小写敏感
XML 标签对大小写敏感。标签
<Letter>与标签<letter>是不同的。必须使用相同的大小写来编写打开标签和关闭标签。<!--由于大小写问题Message标签为被关闭--> <Message>这是错误的</message> <message>这是正确的</message> -
XML 可以嵌套使用,但是不可以交叉使用
<!--错误的交叉使用--> <b><i>This text is bold and italic</b></i> <!--正确的嵌套使用--> <b><i>This text is bold and italic</i></b> -
XML 中的空格会被保留
在 HTML 中会把多个连续的空格字符裁减(合并)为一个;在 XML 中,文档中的空格不会被删减。
-
XML 以 LF 存储换行
LF 换行即使用
\n符号表示;还有一种换行 CR 换行,即用符号\r表示。
-
XML解析
DOM(Document Object Model)文档对象模型:就是把文档的各个组成部分看做成对应的对象。会把xml文件全部加载到内存,在内存中形成一个树形结构,再获取对应的值。
-
常见解析工具:
JAXP:SUN公司提供的一套XML的解析的API
JDOM:开源组织提供了一套XML的解析的API-jdom
DOM4J:开源组织提供了一套XML的解析的API-dom4j,全称:Dom For Java
-
SAX解析
一边解析一边操作,可以解析比较大的文件。但是不能对文件进行修改
-
Dom解析
-
将文件的所有内容读取到内存中形成DOM树,然后再解析。
-
如果文件较大,影响性能。
-
CRUD操作都是可以的
-
-
优点:
- 大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法。
- 支持XPath。
- 有很好的性能。
-
缺点:大量使用了接口,API较为复杂。
pull:主要应用在Android手机端解析XML
-
dom4j使用方法
-
创建SaxReader对象
SAXReader reader = new SAXReader(); -
设置命名空间 (如果XML使用约束且属性
elementFormDefault值是:qualified,则必须要设置)HashMap<String, String> hashMap = new HashMap<String, String>(); map.put("myKey", "自定义命名空间名");// key的名字自己取 reader.getDocumentFactory().setXPathNamespaceURIs(map); -
SAXReader对象调用read方法,将当前XML文件,转换为Document对象
// 获取字节流FileReader,用缓冲流包装一下BufferedReader Document document = reader.read(缓冲流); -
获取根节点
root = document.getRootElement(); -
通过父签添加子标签(元素),再给子标签添加值
Element element = root.addElement("标签名");//返回值就是要添加的元素对象 element.setText("标签值"); -
添加属性,获取属性对象、属性值
// 给当前标签添加属性:xxx ,值是:xxx Element attribute = linkman.addAttribute("属性名","值"); // 通过当前元素获取属性对象 element.attribute("属性名"); // 通过属性对象attribute获取属性值 attribute.setText("值"); // 通过属性对象attribute获取属性值 String 值 = attribute.getText(); -
获取当前元素标签名与值
```java
String name = e.getName();
String text = e.getText();
```
- 获取子标签(元素)
```java
// 获取指定名字的子标签(元素)
当前标签.element(String name);
// 获取所有子标签(元素)
当前标签.elements();
```
- 删除子元素,必须通过父元素
remove(子元素对象)完成
```java
父元素.remove(子元素对象);
```
-
在dom4j里面提供了两个方法,用来支持xpath
// 获取当前名字的多个节点 selectNodes("xpath表达式"); // 获取一个节点 selectSingleNode("xpath表达式");注:在多层级的xpath使用的语法:
//命名空间:a[@id='b1']/命名空间:元素
案例:
读取xml文件,删除、修改、新增节点
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="9527">
<name>刘德华</name>
<age>62</age>
<address>中国香港</address>
</student>
<student id="13">
<name>稻盛和夫</name>
<age>90</age>
<address>日本东京</address>
</student>
<student id="666">
<name>梅西</name>
<age>35</age>
<address>阿根廷</address>
</student>
</students>
public class XMLRead {
public static void main(String[] args) {
SAXReader reader = new SAXReader();
ArrayList<Student> list = new ArrayList<>();
try {
Document doc = reader.read(new BufferedReader(new FileReader(new File("src/studyDemo/xmlTest/students.xml"))));
Element root = doc.getRootElement();
List<Element> rootElmts = root.elements();
for (Element re:rootElmts) {
Student student = new Student();
student.setId(Integer.parseInt(re.attributeValue("id")));
student.setName(re.element("name").getText());
student.setAge(Integer.parseInt(re.element("age").getText()));
student.setAddress(re.element("address").getText());
list.add(student);
}
} catch (DocumentException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
public class XMLModify {
public static void main(String[] args) {
SAXReader reader = new SAXReader();
try {
// 读取XML文件
Document doc = reader.read(new FileReader("src/studyDemo/xmlTest/newstudents.xml"));
Element root = doc.getRootElement();
// 在根节点下增加新的节点
Element stuEle = root.addElement("student");
stuEle.addAttribute("id", "991");
Element nameEle = stuEle.addElement("name");
nameEle.addText("木村拓哉");
Element ageEle = stuEle.addElement("age");
ageEle.addText("32");
Element addEle = stuEle.addElement("address");
addEle.addText("日本北海道");
// 删除第二个节点
root.elements().remove(1);
// 修改第一个节点的文本内容
Element stu0 = root.elements().get(0);
Element age4stu0 = stu0.element("age");
age4stu0.setText("64");
// 将doc写入XML文件
XMLWriter writer = new XMLWriter((new FileWriter("src/studyDemo/xmlTest/newstudents.xml")));
writer.write(doc);
writer.flush();
} catch (DocumentException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Xpath
XPath 是一门在 XML 文档中查找信息的语言。XPath 是 XSLT 中的主要元素。XQuery 和 XPointer 均构建于 XPath 表达式之上
<?xml version="1.0" encoding="UTF-8"?>
<!--实例xml文档-->
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点:
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates):
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点:
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径:
通过在路径表达式中使用 | 运算符,可以选取若干个路径。
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
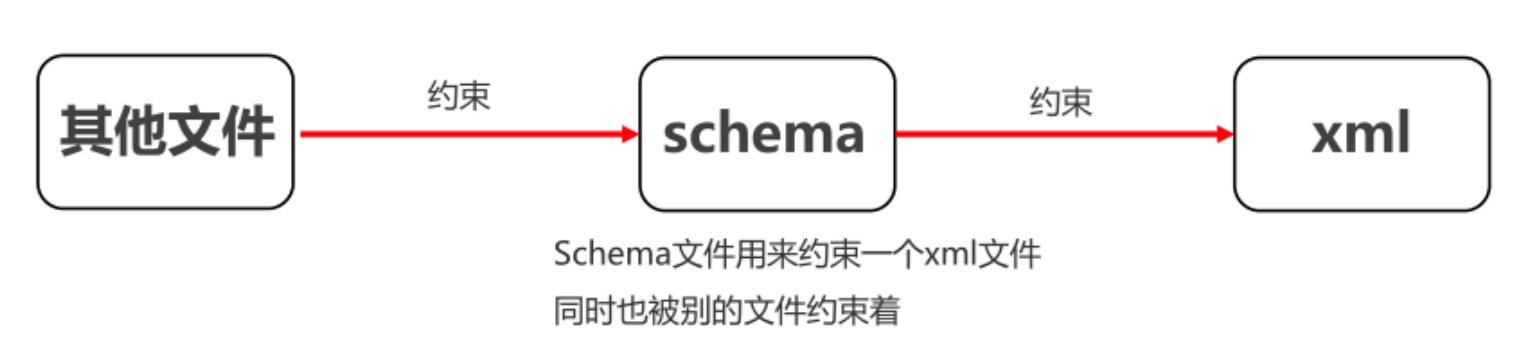
XML约束
DTD约束
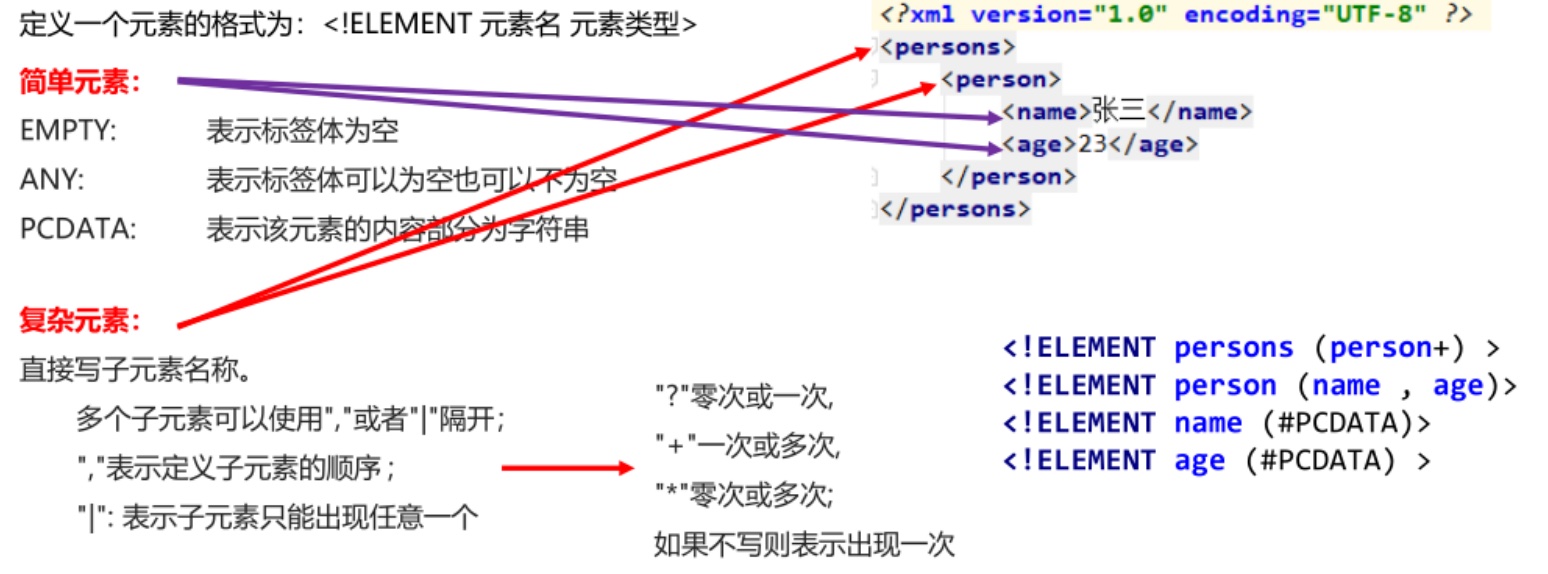
DTD 的目的是定义 XML 文档的结构。它使用一系列合法的元素来定义文档结构。
定义元素的格式:<!ELEMENT 元素名 元素类型>
定义属性的格式:<!ATTLIST 元素名称 属性名称 属性的类型 属性的约束>
-
属性的类型:
CDATA类型:普通的字符串
-
属性的约束:
#REQUIRED必须的#IMPLIED属性不是必需的#FIXED value属性值是固定的
引入DTD约束:
-
引入本地dtd
<!--这是persondtd.dtd文件中的内容,已经提前写好--> <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> <!--在person1.xml文件中引入persondtd.dtd约束--> <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons SYSTEM 'persondtd.dtd'> <persons> <person> <name>张三</name> <age>23</age> </person> </persons> -
在xml文件内部引入
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons [ <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> <persons> <person> <name>张三</name> <age>23</age> </person> </persons> -
引入网络dtd
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons PUBLIC "dtd文件的名称" "dtd文档的URL"> <persons> <person> <name>张三</name> <age>23</age> </person> </persons>
schema约束
schema和dtd的区别:
- schema约束文件也是一个xml文件,符合xml的语法,这个文件的后缀名.xsd
- 一个xml中可以引用多个schema约束文件,多个schema使用名称空间区分(名称空间类似于java包名)
- dtd里面元素类型的取值比较单一常见的是PCDATA类型,但是在schema里面可以支持很多个数据类型
- schema 语法更加的复杂
编写步骤:
- 创建一个文件,这个文件的后缀名为.xsd。
- 定义文档声明
- schema文件的根标签为:
<schema> - 在
<schema>中定义属性:xmlns=http://www.w3.org/2001/XMLSchema - 在
<schema>中定义属性 :targetNamespace = 唯一的url地址,指定当前这个schema文件的名称空间。 - 在
<schema>中定义属性 :elementFormDefault="qualified",表示当前schema文件是一个质量良好的文件。 - 通过element定义元素
- 判断当前元素是简单元素还是复杂元素

<?xml version="1.0" encoding="UTF-8" ?>
<schema
xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itsource.cn/javase"
elementFormDefault="qualified"
>
<!--定义persons复杂元素-->
<element name="persons">
<complexType>
<sequence>
<!--定义person复杂元素-->
<element name = "person">
<complexType>
<sequence>
<!--定义name和age简单元素-->
<element name = "name" type = "string"></element>
<element name = "age" type = "string"></element>
</sequence>
<!--定义属性,required( 必须的)/optional( 可选的)-->
<attribute name="id" type="string" use="required"></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
引入schema约束:
-
在根标签上定义属性
xmlns="http://www.w3.org/2001/XMLSchema-instance" -
通过
xmlns引入约束文件的名称空间 -
给某一个
xmlns属性添加一个标识,用于区分不同的名称空间格式为:
xmlns:标识="名称空间地址",标识可以是任意的,但是一般取值都是xsi -
通过
xsi:schemaLocation指定名称空间所对应的约束文件路径格式为:
xsi:schemaLocation = "名称空间url 文件路径"
<?xml version="1.0" encoding="UTF-8" ?>
<persons
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itsource.cn/javase"
xsi:schemaLocation="http://www.itsource.cn/javase person.xsd"
>
<person id="001">
<name>张三</name>
<age>23</age>
</person>
</persons>